BERT-Large: Prune Once for DistilBERT Inference Performance

Compress BERT-Large with pruning & quantization to create a version that maintains accuracy while beating baseline DistilBERT performance & compression metrics.

Model Compression and Efficient Inference for Large Language Models: A Survey

PipeBERT: High-throughput BERT Inference for ARM Big.LITTLE Multi-core Processors

Qtile and Qtile-Extras] Catppuccin - Arch / Ubuntu : r/unixporn

Distillation of BERT-Like Models: The Theory
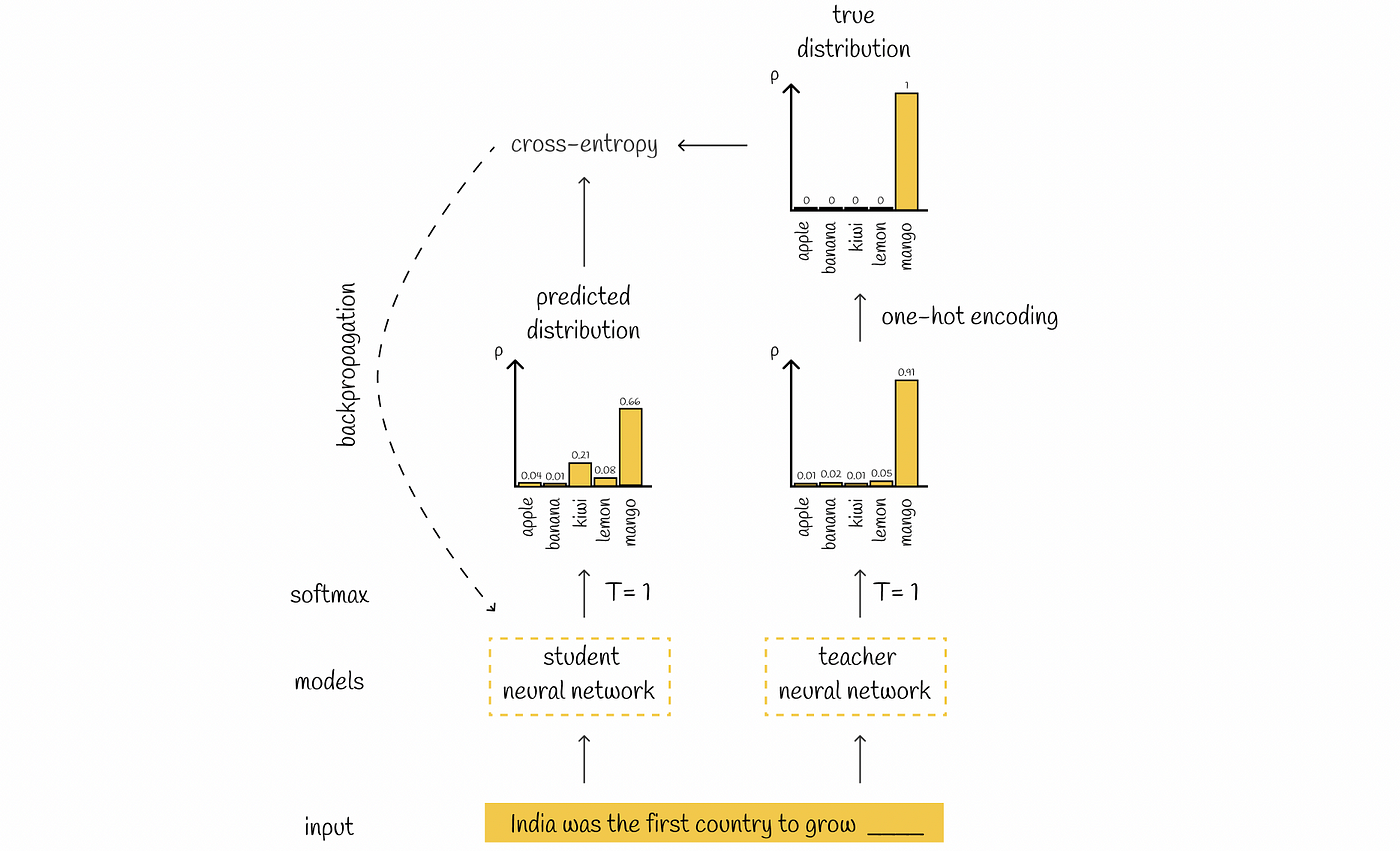
Large Language Models: DistilBERT — Smaller, Faster, Cheaper and Lighter, by Vyacheslav Efimov
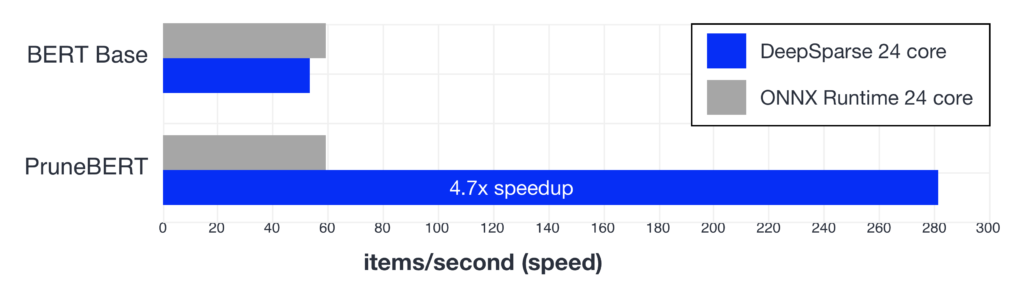
Pruning Hugging Face BERT with Compound Sparsification - Neural Magic
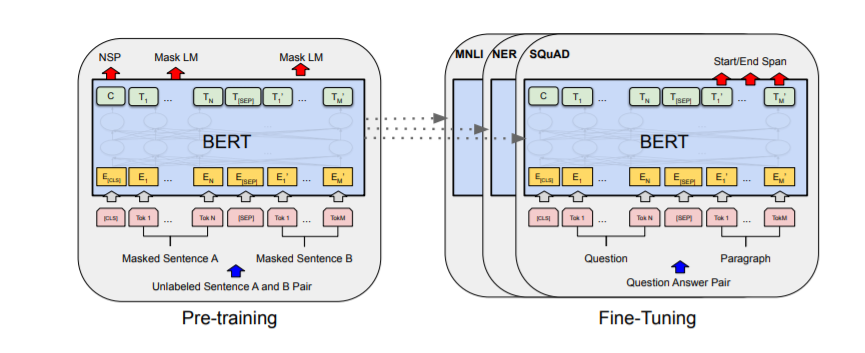
Introduction to DistilBERT in Student Model - Analytics Vidhya
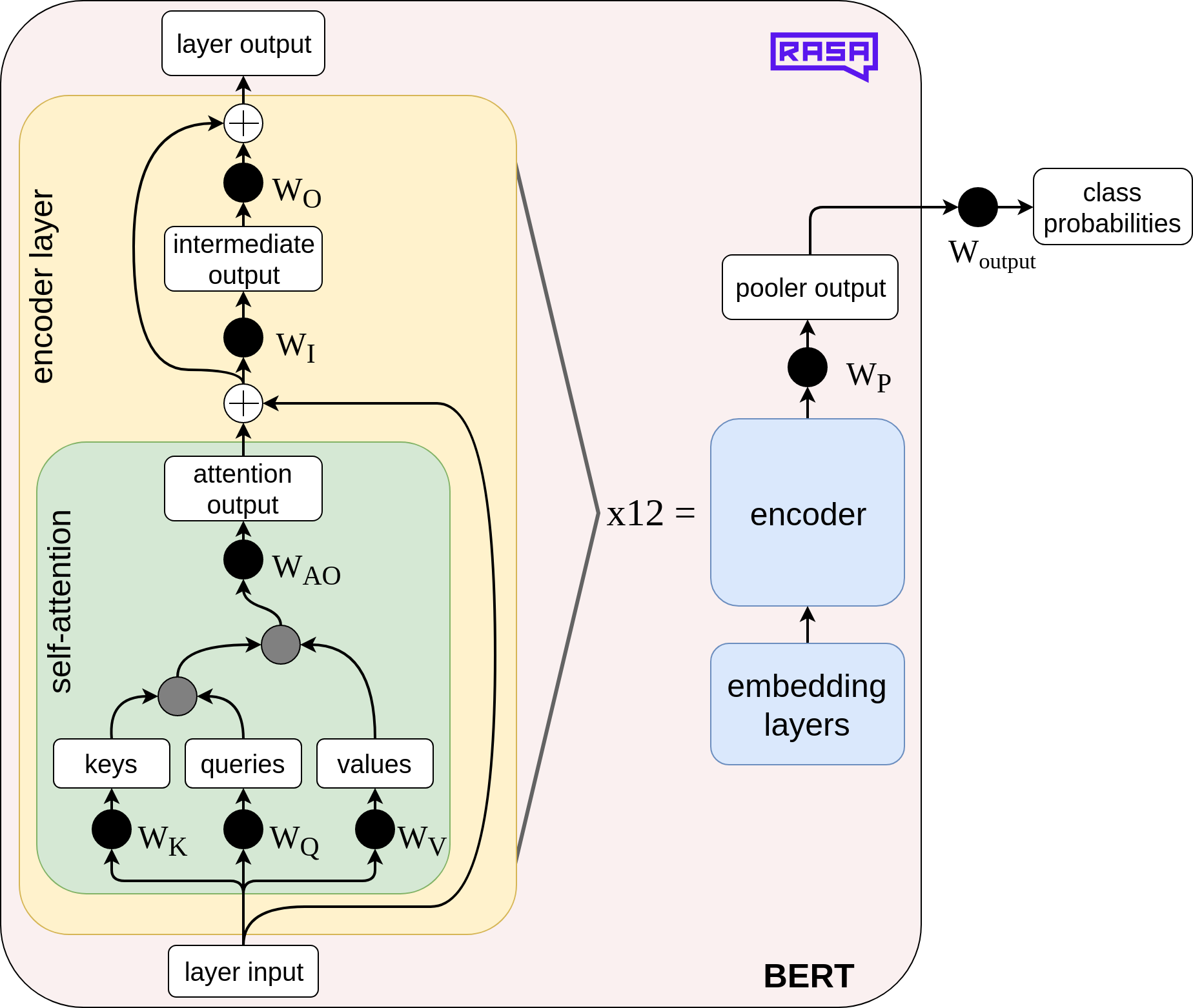
Learn how to use pruning to speed up BERT, The Rasa Blog

Throughput of BERT models with a different number of heterogeneous
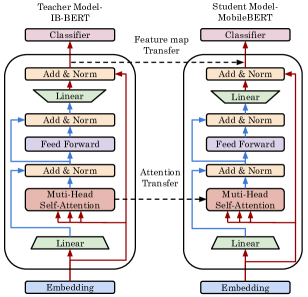
2307.07982] A Survey of Techniques for Optimizing Transformer Inference




/product/76/8428811/1.jpg?2791)

