Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.

arxiv-sanity

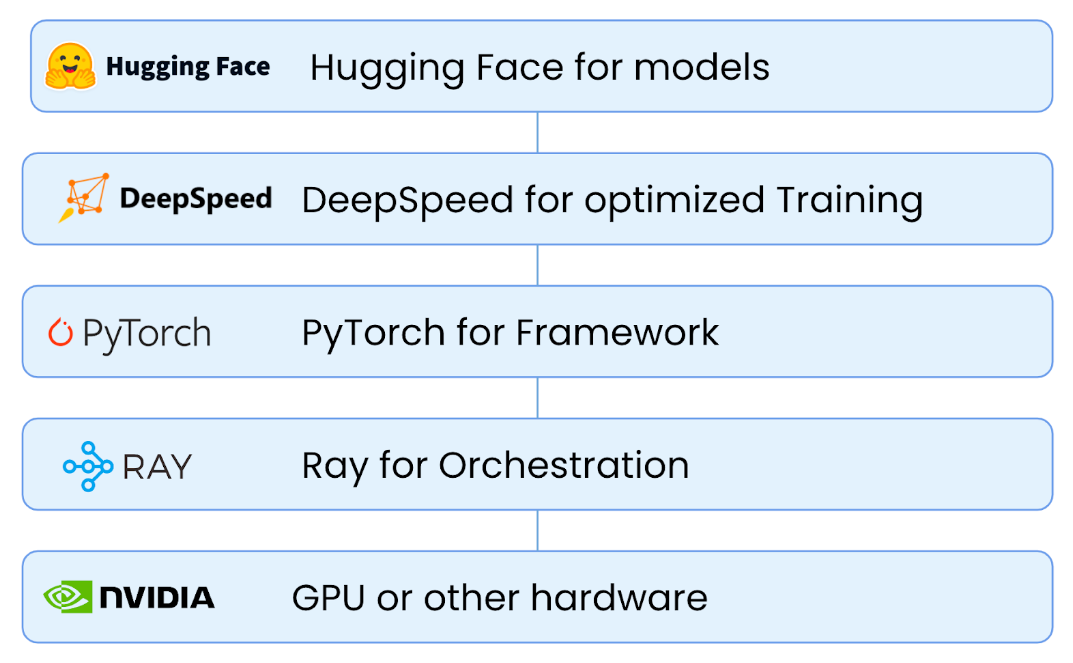
5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds

Electronics, Free Full-Text
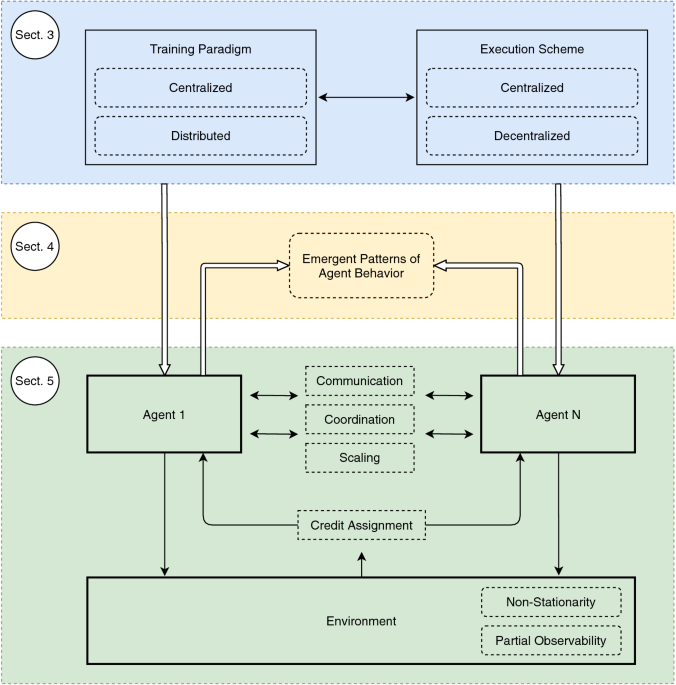
Multi-agent deep reinforcement learning: a survey

RLHF & DPO: Simplifying and Enhancing Fine-Tuning for Language Models

Mina Khan (@minakhan01) / X

Spectra - A New Paradigm for Exploiting Pre-trained Model Hubs
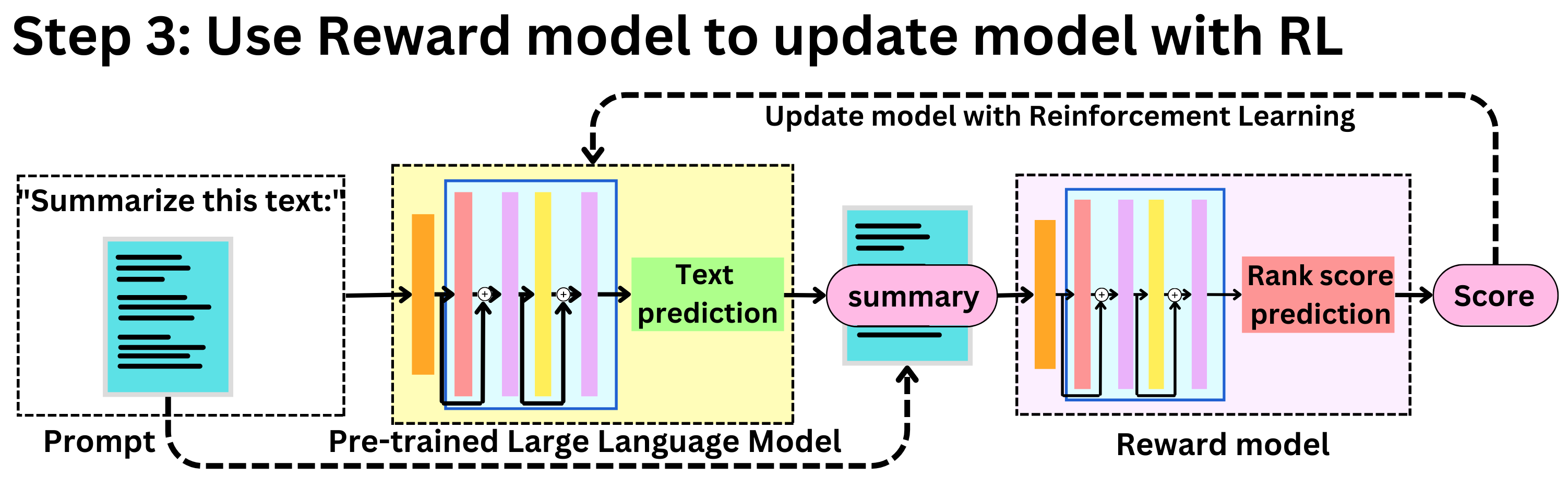
The AiEdge+: How to fine-tune Large Language Models with Intermediary models

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds
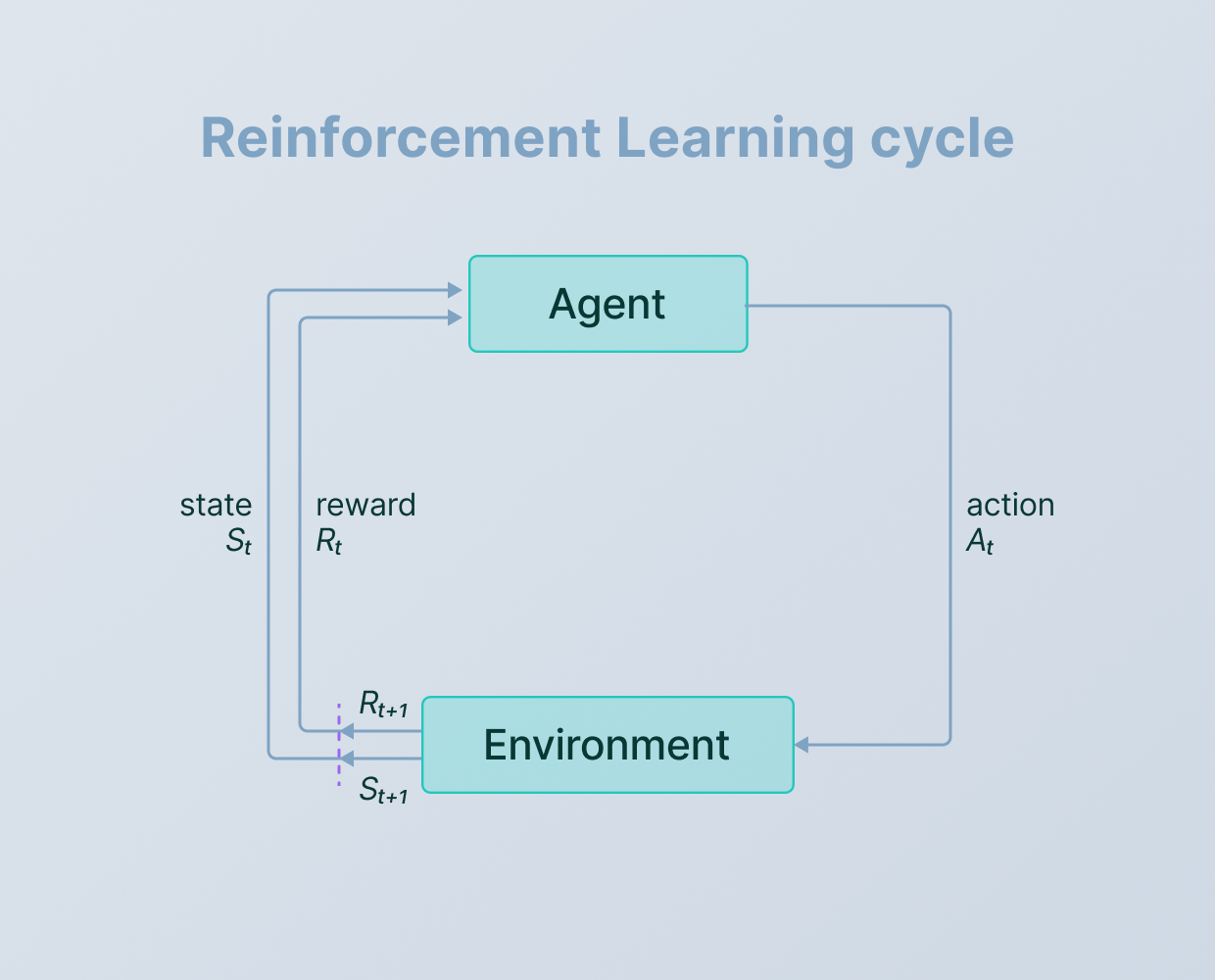
Deep Reinforcement Learning: Definition, Algorithms & Uses
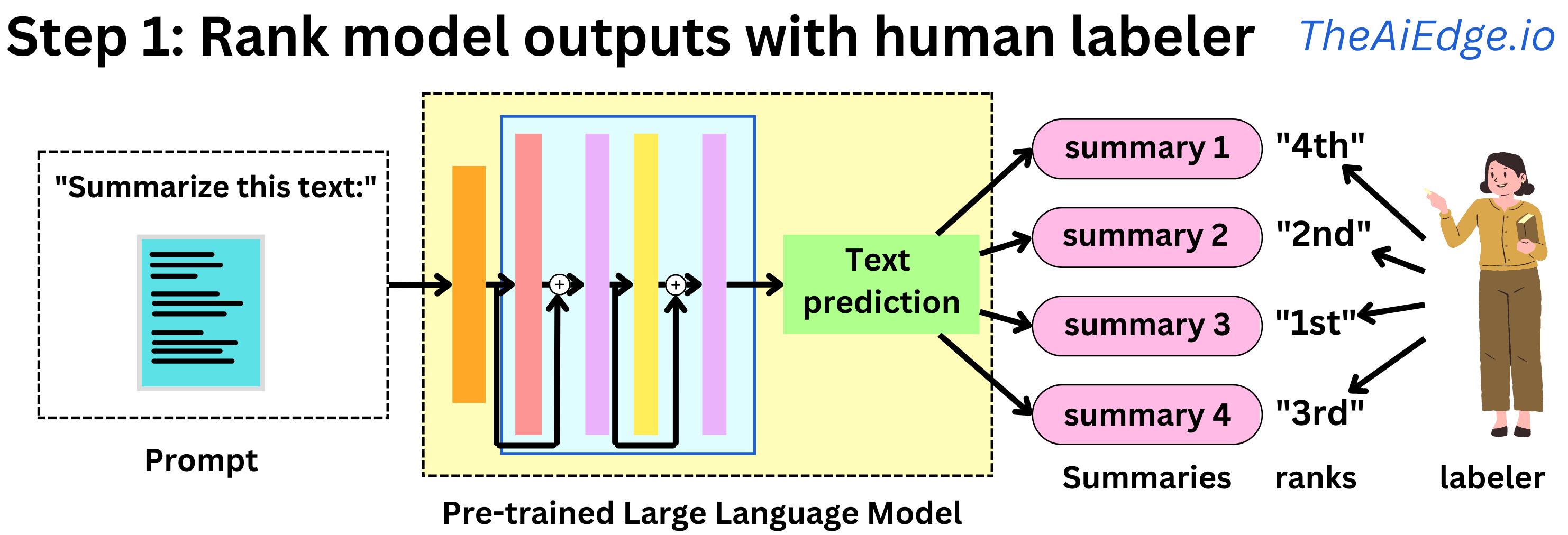
The AiEdge+: How to fine-tune Large Language Models with Intermediary models

RLHF & DPO: Simplifying and Enhancing Fine-Tuning for Language Models
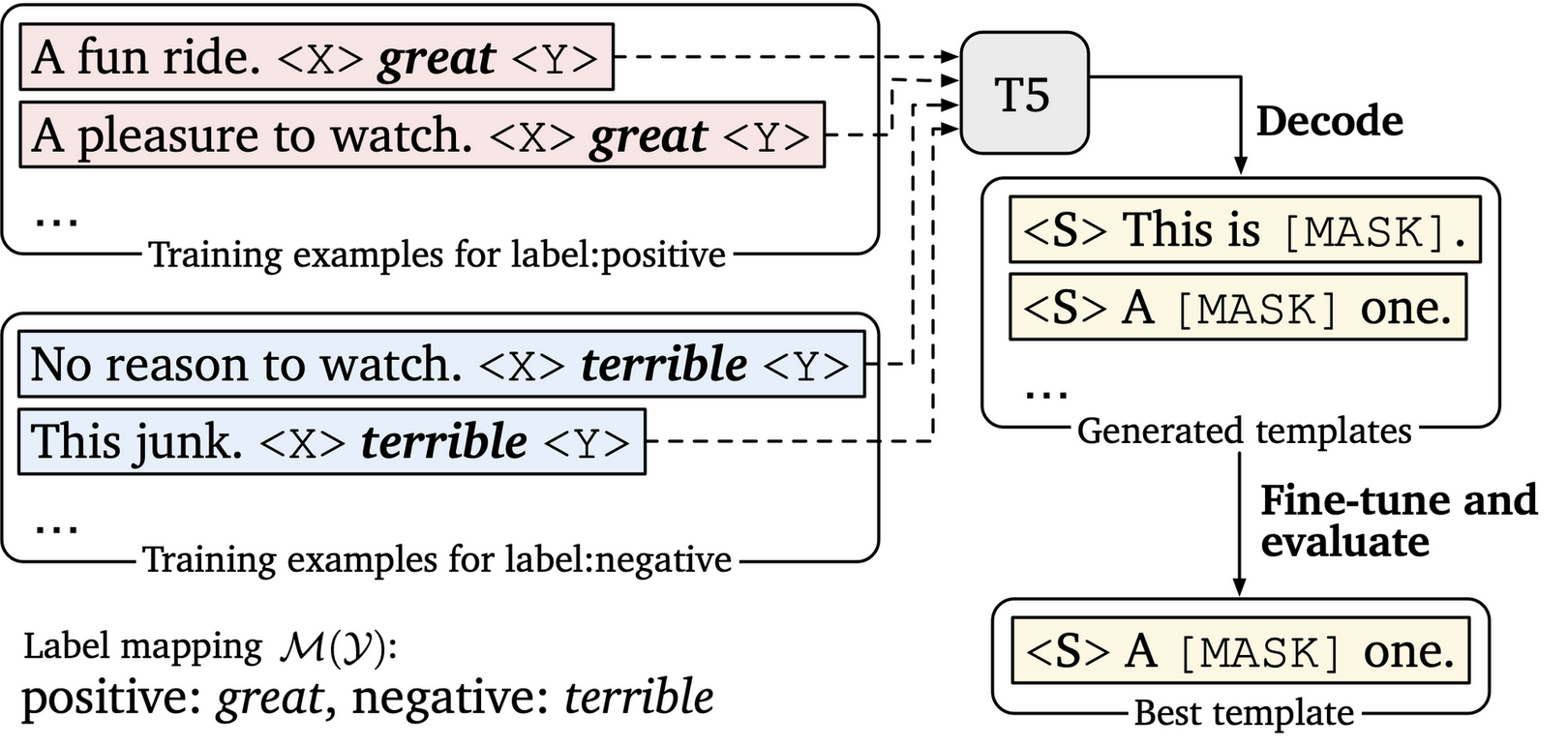
Prompting: Better Ways of Using Language Models for NLP Tasks