As language models become increasingly common, it becomes crucial to employ a broad set of strategies and tools in order to fully unlock their potential. Foremost among these strategies is prompt engineering, which involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing theContinue reading "The LLM Triad: Tune, Prompt, Reward"
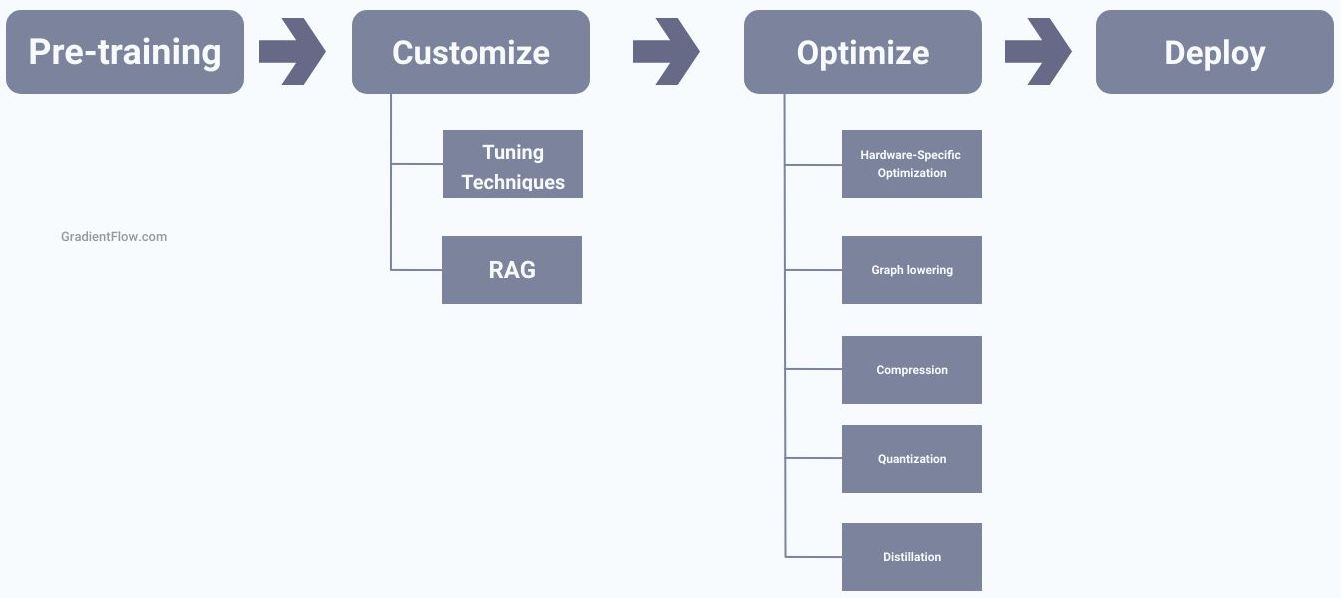
7 Must-Have Features for Crafting Custom LLMs
.png)
A Comprehensive Guide to fine-tuning LLMs using RLHF (Part-1)

Building an LLM Stack Part 3: The art and magic of Fine-tuning
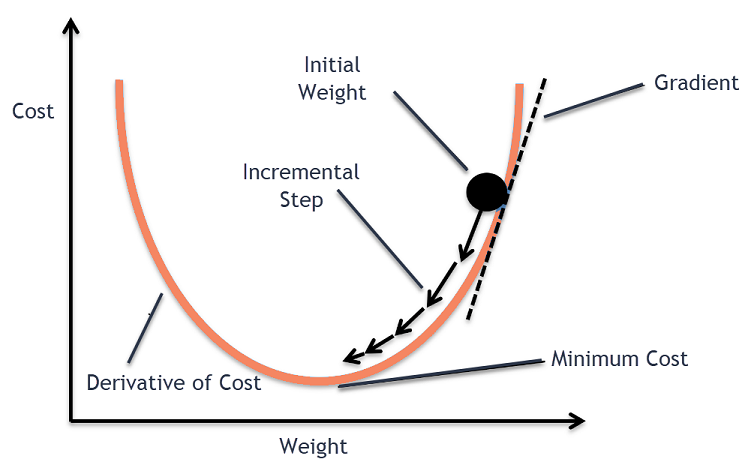
Demystifying Large Language Models for Everyone: Fine-Tuning Your Own LLM. Part 1/3, by Jair Neto
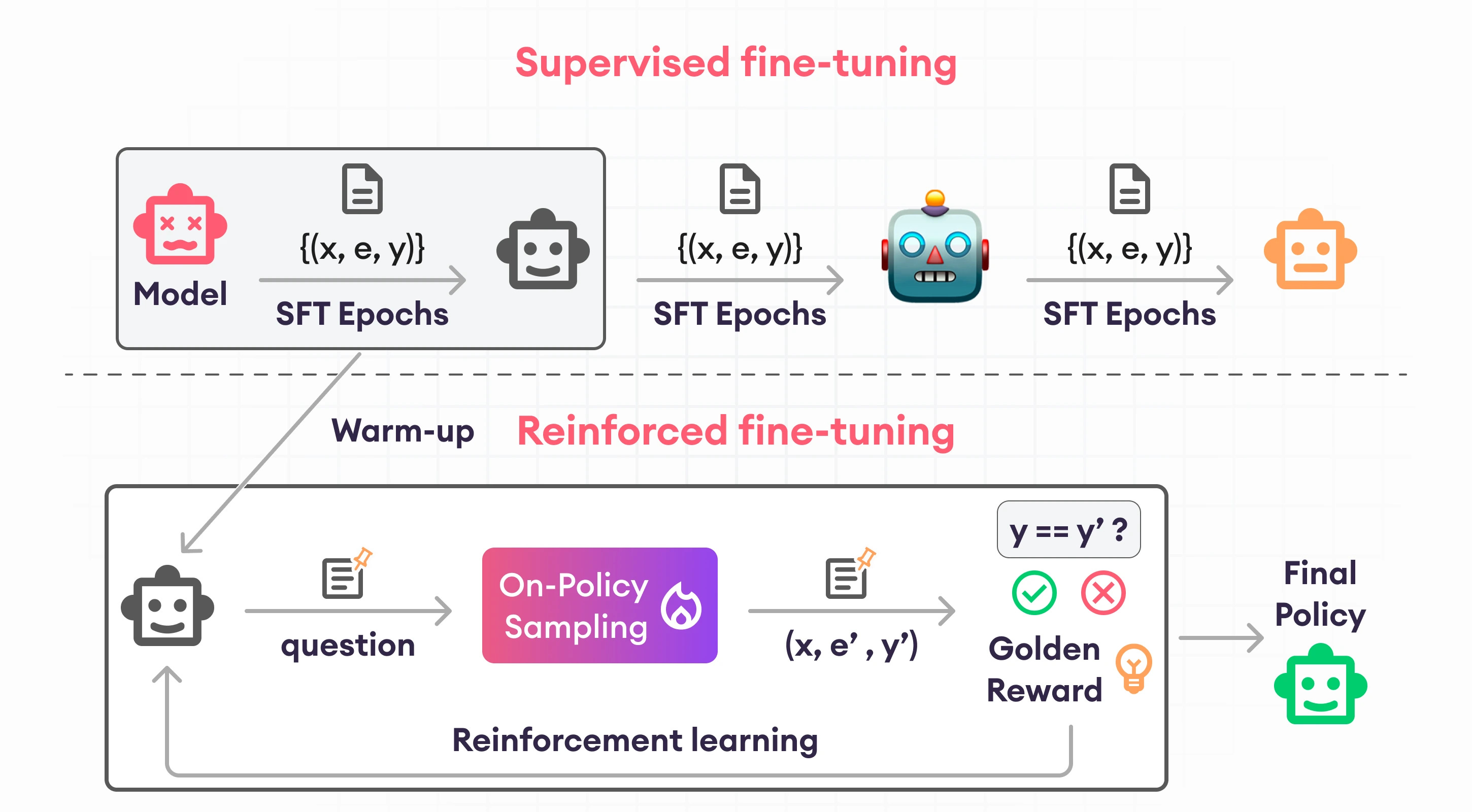
Edge 377: LLM Reasoning with Reinforced Fine-Tuning
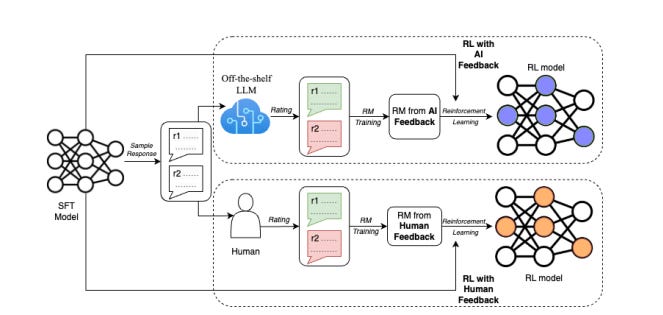
Fine-Tuning LLMs with Direct Preference Optimization

2023 Australasian Anaesthesia – Blue Book by anzca1992 - Issuu

The LLM Triad: Tune, Prompt, Reward - Gradient Flow

LMOps/README.md at main · microsoft/LMOps · GitHub
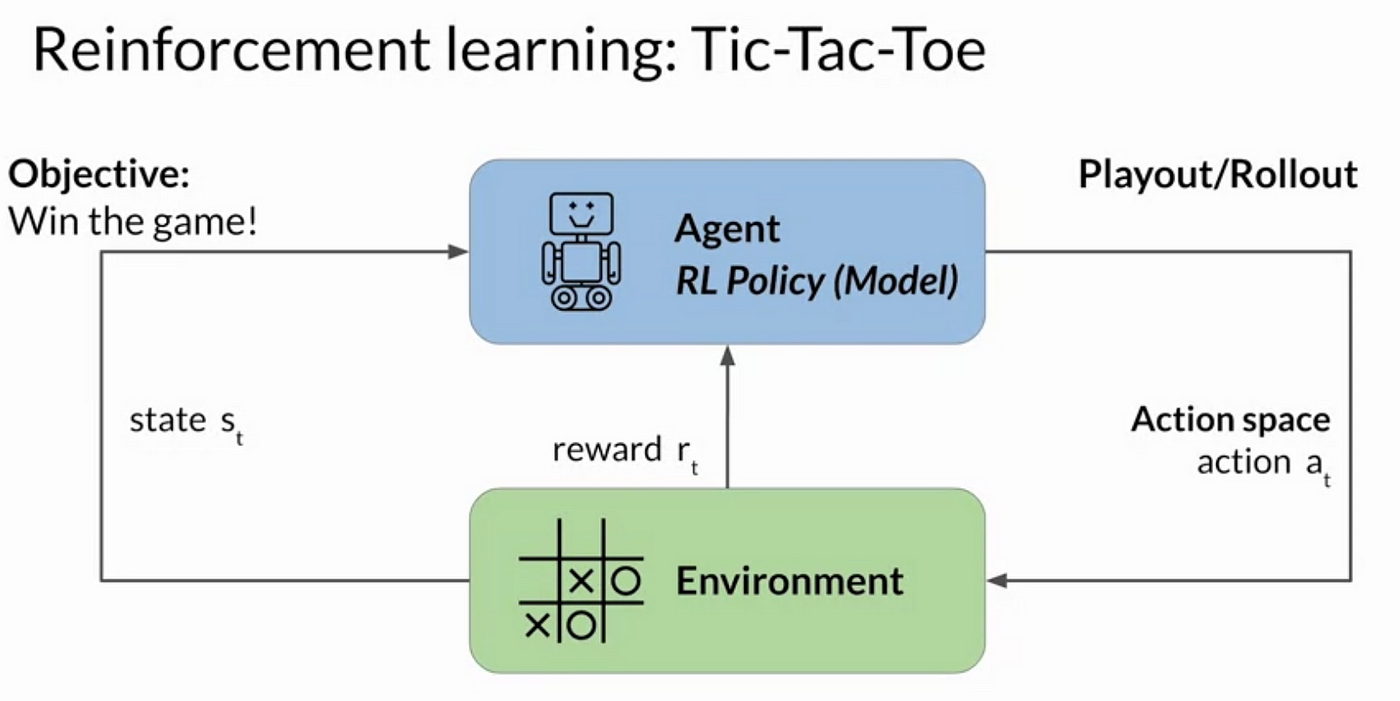
Reinforcement Learning from Human Feedback (RLHF), by kanika adik

Understanding RLHF for LLMs

Building an LLM Stack Part 3: The art and magic of Fine-tuning

大模型的三大法宝:Finetune, Prompt Engineering, Reward_51CTO博客_大模型训练

Retrieval-Augmented Generation for Large Language Models A Survey, PDF, Information Retrieval