The Battle of the Compressors: Optimizing Spark Workloads with
Hello! Hope you’re having a wonderful time working with challenging issues around Data and Data Engineering. In this article let’s look at the different compression algorithms Apache Spark offers…
Avro vs Parquet. Let's talk about the difference between…, by Park Sehun

Organize your data lake using Lighthouse, by Gergely Soti, datamindedbe
Spark Convert Parquet file to Avro, by Naveen Nelamali, SparkByExamples

Spark on K8s — Send Spark job's Metrics to DataDog Using Autodiscovery, by James (Anh-Tu) Nguyen, Geek Culture

Spark partitioning: full control. In this post, we'll learn how to…, by Vladimir Prus

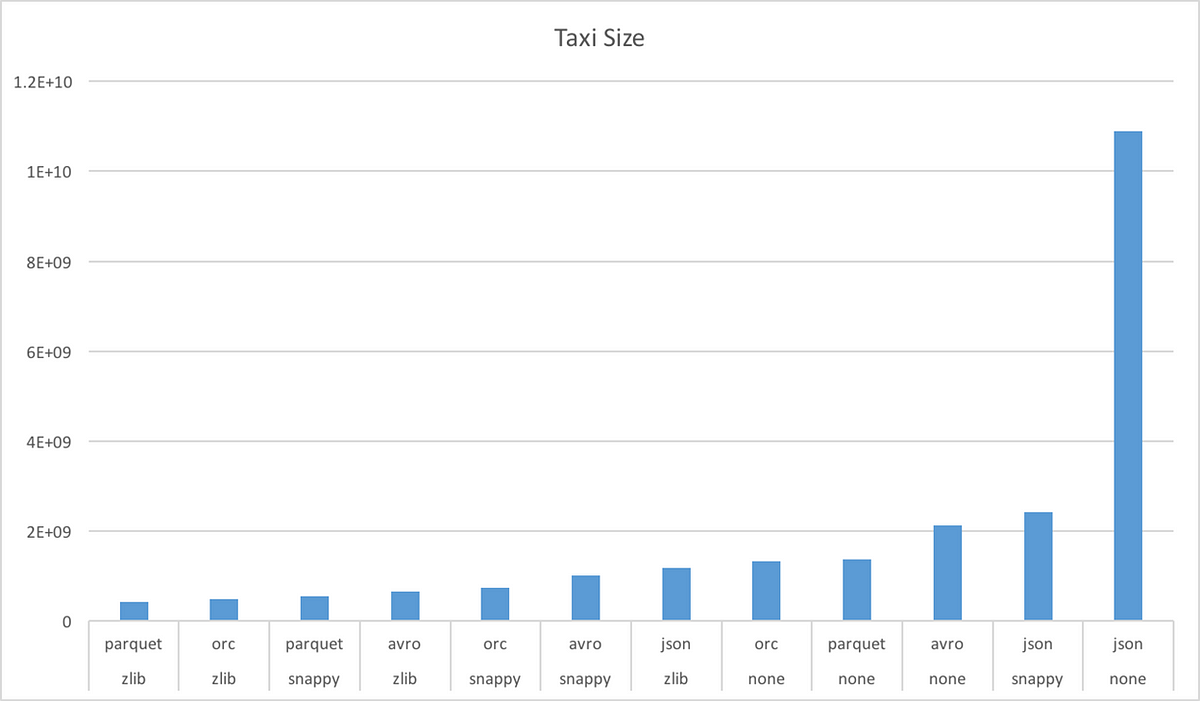
The Battle of the Compressors: Optimizing Spark Workloads with ZStd, Snappy and More for Parquet, by Siraj

Load Data using EMR Spark with Apache Iceberg, by Vishal Khondre

Advanced Spark Tuning, Optimization, and Performance Techniques, by Garrett R Peternel
Advanced Spark Tuning, Optimization, and Performance Techniques, by Garrett R Peternel

Load Data using EMR Spark with Apache Iceberg, by Vishal Khondre
Pyspark — save vs. saveToTable. A cautionary tale of side effects that…, by Ivelina Yordanova
Type safety and Spark Datasets in Scala, by Manish Katoch

Load Data using EMR Spark with Apache Iceberg, by Vishal Khondre
Spark + Cassandra, All You Need to Know: Tips and Optimizations, by Javier Ramos
Pyspark — save vs. saveToTable. A cautionary tale of side effects that…, by Ivelina Yordanova




:strip_icc():format(webp)/kly-media-production/medias/4165980/original/092638000_1663743008-park_min.jpg)


